
De plus en plus pénible, nécessite des contorsions pour pouvoir associer des photos à un point de passage par exemple. Pour y arriver il faut même parfois changer le nom des points…
Topoguide, recherche par chaine de caractères dans le titre plus assez sélective
Saisit l’ID du point de passage à la place de son nom, il y aura qu’une seule proposition.
Mais ca suppose d’ouvrir la page du point dans un autre onglet (mais pareil que pour modifier son nom)
1 Like
Quel est algo utilisé pour la recherche ?
Ca ressemble à une distance de Levenshtein.
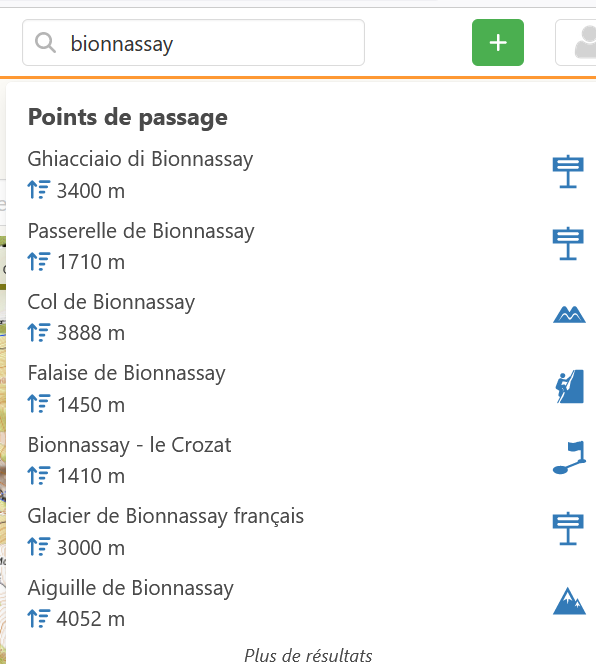
Je reprend l’exemple cité plus haut « goléon » :
« refuge du goléon » --> distance = 10
« golegghorn » --> distance = 5 (donc d’un point de vue machine, c’est normal qu’il sorte avant celui qu’on aimerait)
Il est effectivement difficile de faire comprendre à un humain que les lettres avant comme « le » ont autant d’importance (pour un algo/machine) que des caractères aléatoires (mais proche) en fin de chaine.
Moins y’a de caractères, plus ça laisse de choix de trouver quelque chose d’autre (donc incohérent).
Je vois principalement 3 groupes qui font que nos recherches ne donnent pas les résultats espérés.
Groupe 1 : Ceux où l’on ne précise pas « le »/« la »/« les »/« l’ » (par fainéantise)
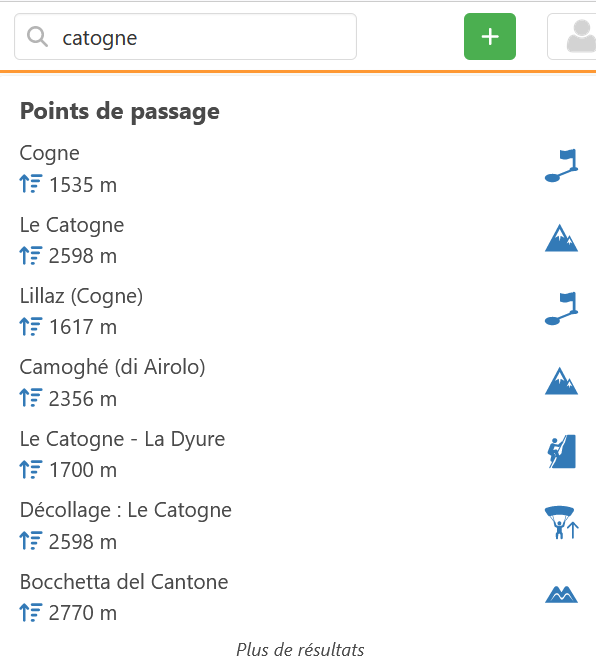
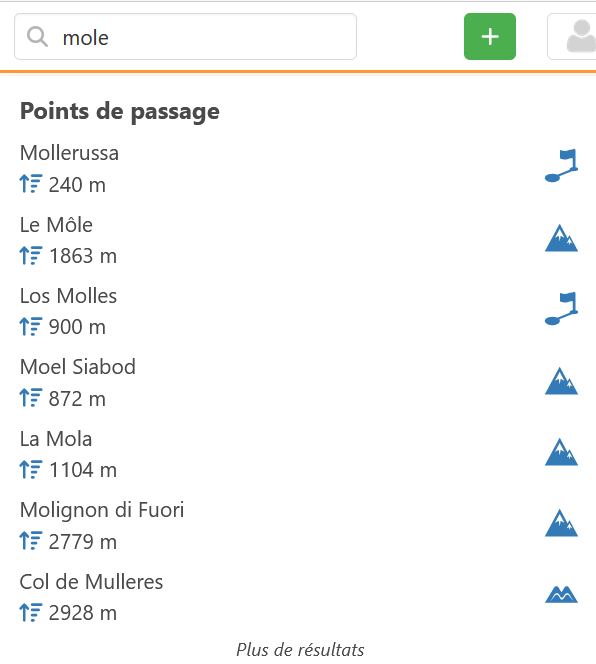
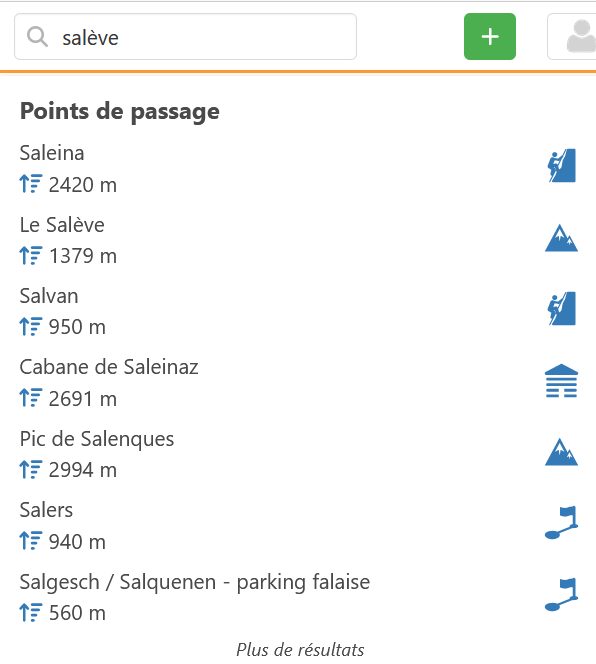

Groupe 2 : Ceux où l’on est sûr du nom, mais pas du type « aiguille »/« dent »/« mont »/« pic » (par méconnaissance)
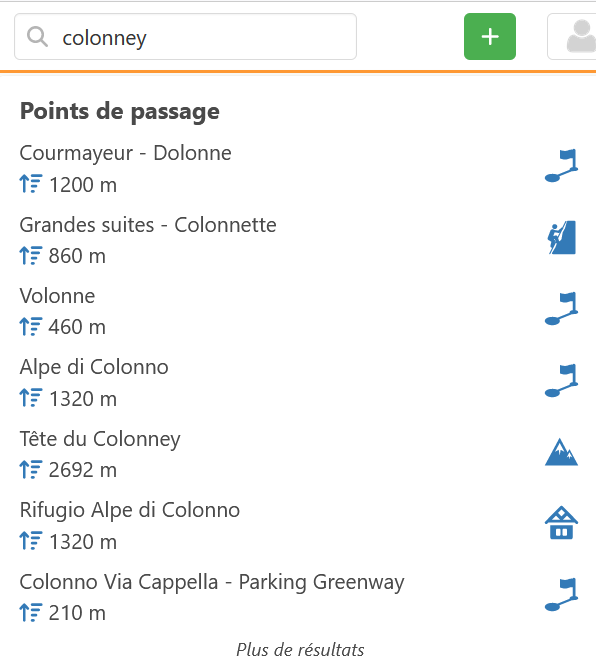
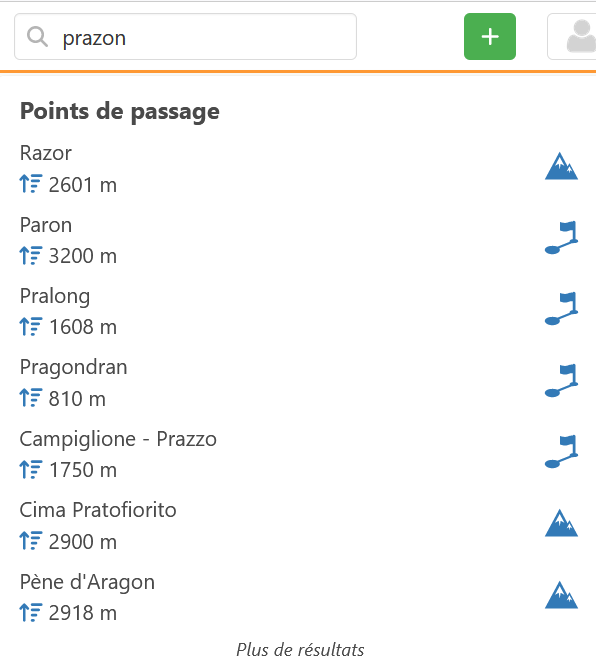
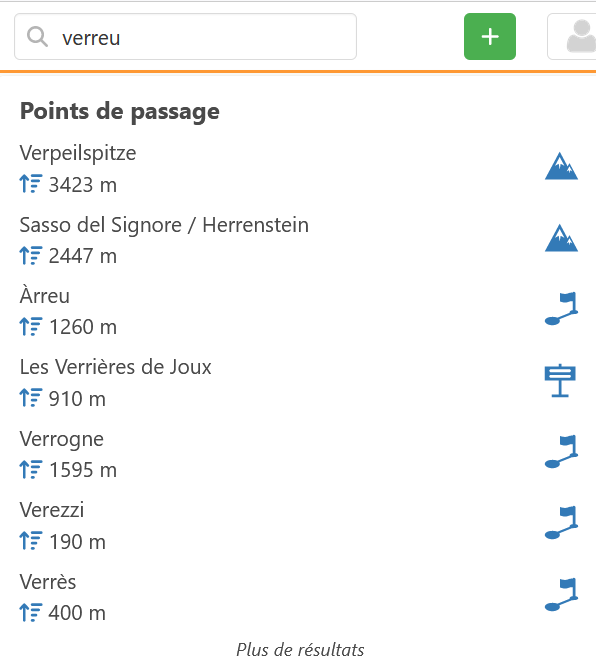
Groupe 3 : Ceux où l’on recherche exactement ce qui est écrit, mais ne sort pas en premier (et ça reste un mystère !)
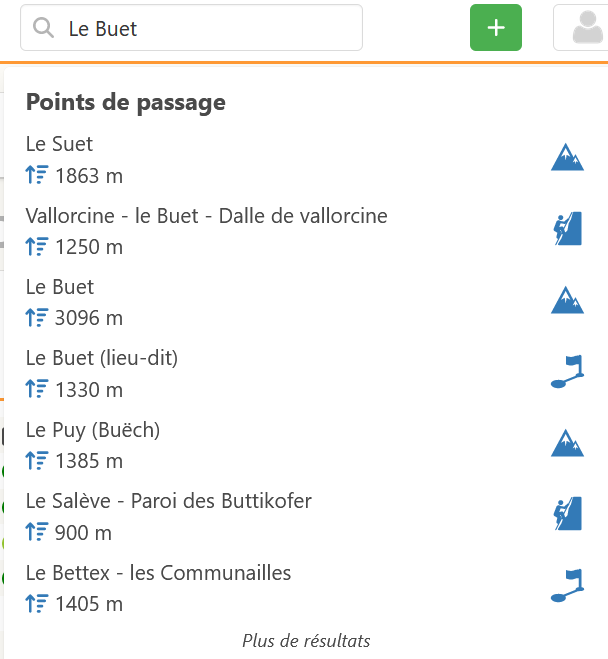
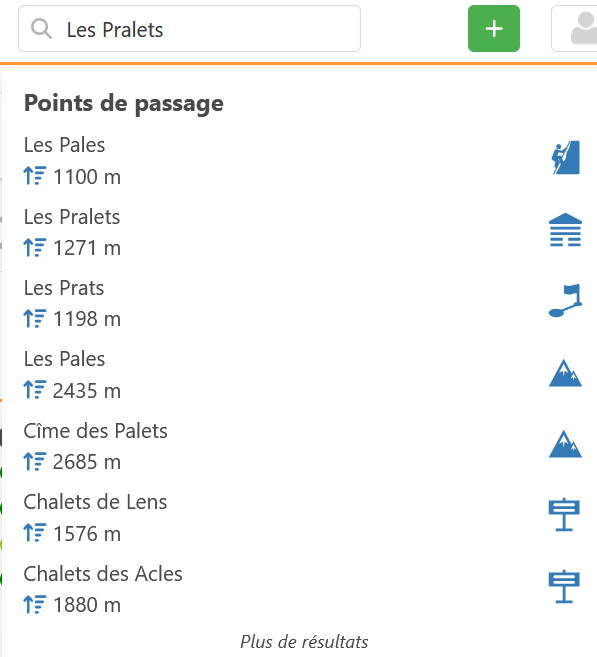
Est-ce que l’ensemble des mots usuels du domaine montagne (aiguille, pointe, refuge, lac, col…) pourrait être pris en compte avec une plus forte pondération pour le calcul de la distance entre 2 chaines ?
Ca pourrait être une similarité par rapport aux accents/majuscules qui ne sont [déjà] pas pris en compte.
Est-ce qu’on pourrait facilement supprimer les espaces (trim) avant de faire le calcul de distance entre les 2 chaines ?
Voici un exemple où l’on pourrait un peu améliorer les résultats du 1er groupe identifié avec l’exemple où l’utilisateur écrit « saleve » :
« le saleve » --> distance = 3
« saleina » --> distance = 3
« lesaleve » --> distance = 2 (ce qui permet de le faire remonter d’un cran)
J’ai fait d’autres essais, ça permet toujours de gagner « 1 », mais souvent ne met qu’à égalité avec un nom plus court. Donc ce serait juste une micro-amélioration.
Autre choix, en utilisant l’algo Jaccard Similarity, qui pourrait aider à trouver plus facilement une sous-chaine dans une chaine ?
https://studymachinelearning.com/jaccard-similarity-text-similarity-metric-in-nlp/
Autre idée : trier les résultats par altitude ? [si leur distance de caractères est identique, ou si une substring est trouvée dans la string]
4 Likes
Je ne sais pas pour l’algorithme, mais « l’outil » utilisé est Elastic Search.
Toute aide sur le sujet est bienvenue, que ce soit les pro d’Elastic Search ou toute personne qui aurait les capacités à comprendre le bidule et aiguiller des devs sur les paramétrages à faire.
2 Likes
Ce qui est sûr, c’est que ça fonctionnait mieux avant. Malheureusement, je n’ai pas noté le moment précis où il y a eu régression. Mea culpa.
On voit bien qu’il y a de l’IA derrière la logique floue utilisée. Clairement, comme souvent en IA, les résultats sont parfois mauvais; et même si statistiquement le pourcentage d’échec est faible, c’est rédibitoire.
En IA un algo trop sophistiqué donne plus facilement des résultats aberrants.
La recherche « colonney » qui sort « Volonne » en est un exemple. L’algo introduit un rapprochement entre « c » et « v » parce que ces lettres sont voisines sur le clavier, pour tenir compte d’une éventuelle faute de frappe. Sauf que le reste du mot n’étant pas identique, ça n’a pas de sens.
Sur une recherche par quelques mots qui sont de facto des mots clé, vouloir tenir compte des fautes de frappe ne fait que dégrader les résultats.
1 Like
Donc d’après la doc, je vois que elasticSearch utilise Levenshtein comme algo. Mais avec une surcouche IA ?
Le Similarity module est peut-être une piste à checker, mais je ne connais pas.
J’ai vu qu’il y a un plugin Elastiknn qui permet de mettre en place d’autre algo :
4 Likes
Il ne faut pas d’algo sophistiqué. On est dans une recherche par expression / mot clé, il faut donc seulement retenir les expressions / mots exacts, les débuts d’expression / mots exacts, à défaut les résultats à +/- un caractère, à défaut les résultats à +/- 2 caractères…
PS: On est dans le domaine de l’IA si les résultats de l’algo sont utilisés comme données qui interviennent dans l’algo ou si on anticipe une possible variation des données (fautes de frappes, expressions amputées etc.)
C’est possible que le problème remonte à 2 ans et demi et soit agravé par plus de documents.
Pas la peine de polémiquer, il n’y a aucun reproche fait aux devs. Si il y a un reproche à faire, c’est à moi-même de n’avoir pas signalé le PB la première fois que je l’ai constaté.
L’IA c’est quand il n’y a pas de séparation entre données et programmes.
Désolé, mais c’est la plus simple et la meilleure définition de l’IA.
L’IA est ma spécialité depuis 1983. Ce qu’on entend ces dernières années, c’est du marketing.
Ok il n’a pas d’IA là dedans
Un bête calcul de distance pas adapté du tout à la recherche par mots clé.
Mais j’ai du mal à comprendre comment l’égalité stricte avec l’expression à rechercher n’est pas en première position dans la liste de résultat. Ou comment l’égalité stricte d’un nom recherché ne fait pas aparaitre le résultat avant des variantes de ce mot.
Le calcul pour évaluer comment ordonner est ce qu’il y a plus difficile à ajuster, et la complexification est rarement la solution. Par exemple, dans un système de traduction automatisée, c’est l’égalité complète d’une phrase (ou d’un groupe de mot) qui donne les meilleurs résultats.
Bonjour @plopluplapi, tu semble bien maitriser le système Elasticsearch et Github.
Ne veux tu pas donner un coup de main afin d’améliorer l’optimisation et donc le code de ce truc dans Camptocamp?
Nous recherchons depuis plusieurs mois un développeur maitrisant Elasticsearch mais introuvable jusqu’à maintenant.
Si vous connaissez un développeur ayant ces compétences, n’hésitez pas à l’ammener ici 
Avant, ça ne trouvait que les titres qui contiennent 6174.
La recherche d’image par titre fonctionnait correctement en juin 2021 date de la modification des titres des photochromes pour pouvoir les retrouver par numéro, en même temps que la mise à jour du champ « Auteur ».
Si le paramétrage des sous-programmes de recherche n’a pas été modifié, c’est qu’il y a eu utilisation d’une nouvelle version de sous-programme ou de bibliothèque de sous-programmes.
Oui, le seul problème du calcul de distance en fonction actuellement est qu’il n’est pas adapté. Notamment parce qu’il est appliqué à la totalité de la chaine de caractères et pas aux mots.
Ca n’est pas choquant si la recherche par Sormiuo ne trouve rien; par contre, que ça trouve Bormio est un problème.
Est-ce qu’une solution, partielle et ne résolvant pas le fond du problème, ne serait pas de faire, comme sur Wikipédia, des pages de renvoi? Concrètement, créer une page « Sormiou » qui renverrait à « Calanque de Sormiou »? Parce que s’il est effectivement plus propre que notre page du topoguide soit intitulée « Calanque de Sormiou », et qu’elle doit donc rester telle, en revanche il est évident que les utilisateurs qui vont la rechercher (moi le premier) taperont « Sormiou » tout court dans le moteur de recherche.
1 Like
Pouquoi se compliquer la vie ? Avant ça fonctionnait.
Pour un utilisateur lambda ça ne compliquera rien, au contraire. Les recherches par mot clef sont entrées dans les moeurs, on ne tape plus l’intégralité des mots recherchés mais les plus importants puis soit les suggestions de recherche permettent de trouver le résultat, soit on clique sur « entrée » et les résultats pertinents apparaissent. De plus les permutations de lettres sont finalement assez rares, les fautes de frappe les plus nombreuses sont d’abord les doublons (ou plutôt leur manque, écrire -l plutôt que -ll) et un mauvais orthographe, puis les tpuches claviers proches, surtout sur smartphone (et je viens d’en faire l’exemple que je ne corrige pas volontairement).
C’était quand même pas fou non plus. C’était courant de passer par Google pour trouver le topo qu’on voulait. Maintenant ça ne marche plus autre problème.
1 Like
je répondais à la création de pages de renvoi qui est une complication inutile (désolé pour l’idée).
La recherche par mot clé comme tu le décris est ok.
Ce qui pose problème est la dillution des bons résultats au milieu des résultats abérants et pire, dans les listes de choix dont la longueur est limitée, les résultats pertinents disparaissent. Ce qui peut être bloquant pour associer des objets, malgré les possibilités multiples pour associer qui suffisent parfois à contourner le problème.
Dans le fonctionnement de la version actuelle, il y a au minimum un problème de tri dans la restitution de la liste sélectionnée par la recherche: les résultats les plus proches ne sont pas les premiers sur la liste.
Quand on sait à peu près où se trouve ce qu’on cherche, c’est bien d’utiliser la recherche par carte, (enfin ça aide si l’outil externe de recherche et positionnement de la carte refonctionne correctement)
Je serais un peu plus prudent quant à mon jugement relatif à une solution déployée par une structure aussi importante, et efficace, que Wikipédia, mais bon…
1 Like
Wikipédia est un outil très « primitif » informatiquement parlant. Ce ne sont que des pages de texte avec des liens.
Le site C2C est une base de données structurées qui publie ces données sous forme de pages
Là où wikipédia crée des pages de renvoi, dans une base de donnée structurées comme C2C, il serait possible d’associer directement un titre à des mots-clé sans créer de pages qui renvoient sur d’autres pages.
Une solution au rabais serait de placer des synonymes dans les titres de page, comme pour les sommets en plusieurs langue non gérées dans C2C.