
Si c’est une machine de guerre (terme plutôt péjoratif) pourquoi ces lourdingues pages de renvoi qui deviennent fausses si les pages changent de nom ?
Et comment passe-t-on d’un texte à une information structurée, le texte ayant une entropie plus grande que l’information structurée ?
Topoguide, recherche par chaine de caractères dans le titre plus assez sélective
C’est ce que je dis, c’est primitif. On veut faire de la base de données structurée en partant d’une informatique documentaire. C’est une usine à gaz qui cumule les inconvénients des deux systèmes. De la redondance en veux-tu en voilà, des clés pas indépendantes, des traitements différés et pas l’ouverture et la souplesse d’une informatique documentaire (on demande à l’utilisateur de faire du codage dans le document !). Par exemple, gérer une bibliothèque de photos sur wiki est une plaie comparé à un outil simple comme flickr.
Arrete de te prendre la tête, tu as affaire a une sommité en sciences (presque toutes ) en geopolilitiqie ,en théologie et maintenant en informatique ,bientôt prix Nobel lequel ? je ne sait pas
4 Likes
Ah oui, pas que de photos mais d’images et de multimédia en général :
T’inquiète, je le refuserais, Nobel était un industriel peu recommandable qui révait d’inventer une arme de destruction massive.
Ouf on est rassure
Vous êtes sérieux à vous taper dessus littéralement sans aucune raison ? Votre but commun c’est d’améliorer les choses.
Une question de néophyte, j’ai des notions de programmation mais aucune notion dans les concepts plus évolués dont il est question :
Serait-il possible de mettre en tête des recherches, les résultats avec des correspondances strictes de débuts de mots, accents exclus ? Et ensuite seulement, la recherche avec IA ou je ne sais pas comment appeler ça ? Et idéalement classés par popularité dans les correspondances strictes, avec comme indicateur objectif de popularité, par exemple, le nombre de sorties associées ?
Pour prendre un exemple concret, si je tape « cog », il me trouve Cogne bien bien loin, avec des « col » et points peu populaires avant. Notons que le L est bien loin du G sur le clavier.
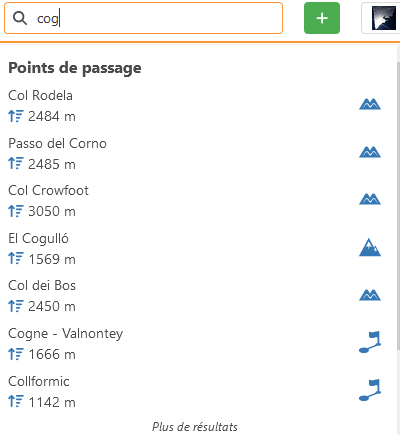
2 Likes
C’est curieux, j’ai moi aussi perçu des changement majeur, il me semble, 1 ou 2 fois dans les derniers ~3 ans. Par exemple à Noel 2022: posté la. Peut-être des mises à jour de la version ElasticSearch, qui aurait changé des options par défaut?
Merci pour les exemples détaillés, ça devrait vachement aider.
Oui! Je trouve que c’est OK de faire du Levenshtein (par exemple quand on part à l’étranger, ou qu’on cherche un nom entendu au détour d’une rencontre).
Par contre (1) faut pas le faire sur le recherches courtes (<6 caractères ?)
(2) et surtout il y a un gros souci d’ordre (ranking), le mot exact qui n’apparait pas en premier par exemple. Les mots « corrigés » doivent avoir des poids inférieurs (=apparaitre plus bas) , et par ex., les « le/la/du » etc il devrait y a moyen de leur donner un poid baucoup plus faibles
Euh je connais Elastic assez superficiellement, mais ça m’agace peut-être suffisemment pour creuser 
4 Likes
Creuse, creuse, s’il-te-plaît, et sois aussi efficace qu’à propos de la carto 
2 Likes
hum c’est un beau projet pour ce week-end venté
je peux commencer sans, mais je pense mais qu’il me faudra un truc qui resemble un peu au contenu actuel de la DB pour tester? je sais pas ce que vaut la « dev database »… si a un moment je peux avoir accès à des vieux backups ça sera utile
La météo pourrie, c’est que du bon pour C2C. Pas autant qu’un bon confinement, mais enfin on ne peut pas tout avoir
J’ai commencé à creuser le code de l’API sur la recherche avec Elastisearch. J’ai une question sur la recherche: à votre avis, est-ce utile de prendre en compte la langue de vos préférences comme critère de recherche ?
Pour moi ce n’est pas utile, on ne recherche que des titres peu importe la langue mais il y a peut-être des cas auxquels je n’ai pas pensé.
1 Like
Pour des sommets du type Cervin ? Matterhorn en allemand, ou Cervino en italien ?
Ça va aussi dépendre de la langue sous laquelle tu utilises le site.
1 Like
Effectivement quand tu cherches Matterhorn, il me sort Cervin.
Mais c’est c’est l’UI qui fait la « traduction ». L’API recherche « mattehorn », et renvoie une liste de résultats comportant les infos sur des documents, dont le titre mais dans toutes les langues. C’est l’UI qui choisit d’afficher la bonne langue selon la langue de l’interface (et si la traduction dans la langue de l’interface n’est pas disponible ça choisit une langue disponible selon un algo).
Par contre je ne sais plus ce que signifie « prendre en compte la langue de l’interface » dans la recherche d’elastic search. C’est peut être juste pour définir un mot approché. Mais sur des noms propres ça ne fonctionne pas trop si on mélange toute les langues. Lors des essais sur la démo de la V6, il me semble qu’on avait vu que c’était impossible d’indexer par langue, car il faudrait que tous les docs soient traduits dans toutes les langues.
1 Like
‹ Monte Perdido › traduit en ‹ Mont Perdu ›.
Mais c’est un cas très marginal, 99,9% des sommets frontaliers ont le même nom, ou un nom totalement différent ( Cervin Matterhorn) où on ne peut pas appliquer de traduction.
Mais si je comprends bien, la recherche sur le nom exact arrivera toujours sur la bonne page : si on est français, soit on cherche Cervin et on arrive directement sur la page Cervin, soit on tape Matterhorn et la recherche amène sur la page traduite en allemand, mais comme on est paramétré en français, c’est la version française de la page qui s’affiche, donc Cervin ?
Bernard
Ok, donc à priori ce n’est pas utile de faire une distinction en fonction de la langue choisie dans les préférences.
oui c’est pour cette raison. La recherche découpe le texte en ngram et dans le code, il y a un boost pour les ngrams (pourquoi ?) et le boost est différent s’il y a une préférence de langue. Je vais regarder dans le code si ce boost sur les ngrams ne se fait pas au détriment du résultat qui match exactement sur les mots, voire si la recherche sur les mots est réellement implémentée (j’ai un doute à ce sujet).
Voici le code python sur la recherche sur un titre. La syntaxe « ngram^2 » signifie que le score de la recherche avec les ngrams est boosté à 2, la valeur de référence étant 1. Si vous avez des idées…
def get_text_query_on_title(search_term, search_lang=None):
fields = []
# search in all title* (title_en, title_fr, …) fields.
if not search_lang:
fields.append(‹ title_.ngram’)
fields.append('title_.raw^2 ›)
else:
# if a language is given, boost the fields for the language
for lang in default_langs:
if lang == search_lang:
fields.append(‹ title_{0}.ngram^2 ›.format(lang))
fields.append(‹ title_{0}.raw^3 ›.format(lang))
else:
fields.append(‹ title_{0}.ngram ›.format(lang))
fields.append(‹ title_{0}.raw^2 ›.format(lang))return MultiMatch( query=search_term, fuzziness='auto', operator='and', fields=fields )
1 Like
Pas sûr que ça ne rentre pas dans les cas de figure mentionnés ci-dessus, mais enfin: il y a beaucoup d’itis qui comportent des noms communs (arête, crête, depuis, etc.), variables donc suivant les langues