
Pas vu d’opposition sur le fond, juste des discussions sur des sujets annexes… Il me semble en tout cas.
Merge PR pour les tags V# and C#
Heu, merci de ne pas modifier les definitions sans prévenir la @Modo_Topo_FR_contact !
Une couenne fait bien une seule longueur, sinon c’est une grande voie. Éventuellement pour les couennes longues (ton exemple de 100m), on peut indiquer qu’il y a un relais intermédiaire facultatif/recommandé. Mais si c’est un relais usuel/obligatoire alors il s’agit d’une GV. Mais oui, il y a régulièrement des GV sur des sites majoritairement en couennes, et il faut pouvoir les inclure ergonomiquement dans une liste de voies.
Le fond de l’article Terrains pour grimper : L’escalade en falaise et la couenne n’a pas évolué depuis sa création en 2008.
Il serait utile de mentionner les couennes avec relai intermédiaire facultatif, la présence de grandes voies dans des secteurs de couenne, dont la première longueur est utilisée comme couenne (et donc usée plus rapidement), les couennes rallongées en grande voie des années après leur équipement initial, etc.
D’ailleurs, dans l’article sur l’escalade en grande voie, il est indiqué qu’une grande voie est à partir de 3 longueurs.
Ce qui est important pour les définitions, est ce qu’on doit cocher dans le champ « type de voie » d’un itinéraire escalade, ou « type de site » dans un point de passage site d’escalade (couenne, grande voie, bloc, psycobloc). Mais actuellement il n’y a pas d’aide contextuelle pour ce champ.
Ah pardon je savais pas.
Mais genre ici les voies avec relais intermédiaire peuvent faire juste 15 ou 20m, c’est pas des grandes voies du tout…
Je ne vois pas où est le pb. On pourra evtl. utiliser C# et V# dans la même table.
C’est pas si simple quand même, notamment dans les couennes dures (7, 8 , 9). Les relais inter, les combinaisons, etc ne sont pas rares. Un exemple : Seynes là où c’est dur sur colos. Il y a quasi systématiquement 2 étages. Tu fais le bas,le haut, tu enchaînes, tu mixes,…
C’est pas aussi mathématique que plus d’une longueur = gv
1 Like
Exemple de topos de couenne du coin qui ont plusieurs longueurs :
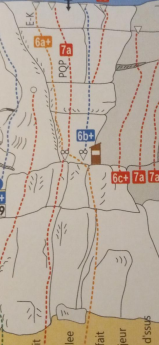

Chaque voie est indiquée en mode « 6 : première longueur 4c+, seconde longueur 5a/5b ». Et on est sur des voies de 20-30 m max. C’est pas de la grande voie (vu qu’une longueur peut faire genre… 5 mètres), c’est de la couenne avec des relais intermédiaires 
Mais bref on diverge 
Avec le C#, on pourra faire :
| 1 | Eh prise, es-tu là ? | 7a | 25 m |
| 2’L1 | Le grand voyage | 5c | 15 m |
| 2’L2 | 6b | 12 m | |
| 3 | Dré dans la mousse | 5b | 20 m |
Ou simplement :
| 1 | Eh prise, es-tu là ? | 7a | 25 m |
| 2 | Le grand voyage - L1 | 5c | 15 m |
| 2 | Le grand voyage - L2 | 6b | 12 m |
| 3 | Dré dans la mousse | 5b | 20 m |
Dans les 2 cas, on perd la numérotation automatique pour tout le secteur, il faut ajouter le numéro à la main (C#2’L1 ou C#2).
Les seuls caractères de non alphanumériques supportés en suffixe du numéro de la longueur sont ’ et "
Oui ça serait cool d’avoir les tableaux, mais ça ne répond pas au besoin d’ici, comme débattu plus haut… On tourne en rond.
OK je laisse tomber, je vais chercher un autre site pour faire mes topos du coup
Oui, très utile.
Je tente une dernière fois de réveiller cette discussion pour obtenir l’approbation de cette PR.
En effet, comme exposé auparavant, il est nécessaire de ne pas utiliser des tableaux génériques ici car nous avons besoin de conserver le sens sémantique des voies d’escalade, qui puissent donc être identifiées ensuite pour générer automatiquement des topos PDF et papier pour les falaises de ma région.
Les tableaux génériques Markdown ne permettent pas de faire ça. Je suis aussi pour activer les tableaux markdown bien sûr, mais leur usage est différent, car il n’indique aucune sémantique permettant de réutiliser les données entrées dans camptocamp.
Si les tables génériques sont utilisées, la modération topoguide choisira une convention pour désigner les topos de couennes dans un souci d’homogénéité, et veillera à ce que cette convention soit respectée (cf le threads sur les vérifications automatiques, il y a bien une chose ou la modération est efficace, c’est dans l’homogénéisation du topoguide).
En conséquence, cette convention sera tout aussi fiable qu’une sémantique faisant partie de la syntaxe.
En clair, tous les topos d’escalade utiliseront ce code (ou une autre, le point est qu’il sera utilisé et commun à tous les topos) :
| V1 | Biographie
| V2 | Burden of dream
La sortie est une table, et le code est aussi identifiable que V# | Biographie. En pratique, si tu as un point de passage de type couenne, et que tu trouves un ligne commancant par « | V<un nombre> », tu peux etre sur à 100% que c’est une liste de voie.
Ou bien je rate quelque chose ?
Au passage, tu peux me montrer l’outil que tu comptes utiliser pour générer automatiquement des topos PDF, je pourrais peut-etre me rendre mieux compte ou ca coince ?
Ben oui.
On veut définir une balise V# ou C# pour ne pas utiliser L#, qui donne un affichage avec L1, L2, …, alors qu’on veut 1, 2, … (tout en conservant V# dans le code, donc la moulinette de @bohwaz ferait la différence entre tableau de couennes et tableau markdown ou html donnant le même affichage).
Et comme méthode alternative, tu proposes de mettre V1, V2, …, y compris à l’affichage.
tu proposes de mettre V1, V2, …, y compris à l’affichage.
Ben non… J’ai mis une convention en précisant, je cite : « ou une autre, le point est qu’il sera utilisé et commun à tous les topos ».
Ben du coup si tu veux 1, 2 … à l’affichage, alors le code sera :
| 1 | Biographie
| 2 | Burden of dream
Tu mettras ben ce que tu veux.
Comment tu fait dans ce cas pour différencier un tableau de voies sportives d’un tableau qui liste d’autres informations par ordre numérique ?
Pour moi ça répond pas vraiment au besoin…
Comme indiqué plus haut dans ce fil, mon patch n’ajoute aucune complexité dans le parseur, ça ne fait que réutiliser une logique qui existe déjà…
1 Like
Soi tu ne réponds pas à mes objections et contre-propositions, on n’avancera pas beaucoup. C’est à toi de voir.
Je suis assez bien placé pour juger de cette complexité. Et j’ai donné avis mon avis plus haut : « elle rajoute un peu de complexité (faible je te l’accorde très volontiers, et tu as d’ailleurs fait le taf très bien) ».
Le souci, c’est que c’est un débat technique, et les autres personnes ne pourront juger que parole contre parole, donc je ne rentrerai pas dans les détails techniques. Mais il y a un fait qui parlera plus facilement à tout le monde, et c’est toi-meme qui l’énnonce :
![]()
Donc pour rajouter cette complexité que tu juges nulle, et moi faible, tu as passé un temps « considérable ».
Et je te crois très volontiers, je suis encore une fois très bien placé pour savoir que tu dis la vérité  . Le parser est vraiment un module qui est compliqué à maintenir et faire évoluer. Et je ne parle pas du jour ou il faudra le migrer.
. Le parser est vraiment un module qui est compliqué à maintenir et faire évoluer. Et je ne parle pas du jour ou il faudra le migrer.
Bref, sauf nouvel élément, mon avis est fait. Mais je ne décide pas. Il serait respectueux envers toi, considérant le travail que tu as fourni, que @CA1 se prononce officiellement, afin de ne pas te laisser dans le doute.
Bonne journée (et ma proposition de te filer un coup de main pour te permettre d’avancer au mieux avec ce qui est possible et raisonnable de faire sur c2c tient toujours ).
C’est quoi ces insinuations ? J’y ai passé un temps considérable car je n’ai jamais fait de Ruby de ma vie, je ne connaissais pas le code de ce site… Ça n’a rien à voir avec la complexité du patch… Qui rajoute… 9 lignes de code…