
Tu peux essayer dans un navigateur vierge de tous cookies stp ?
[Bug] Recherche topoguide - résultats non pertinents
1 Like
Et là ça fonctionne. Bref dans tous les cas, ce qui compte c’est que la recherche du topo soit en cours de réparations !
3 Likes
Autre exemple de dysfonctionnement:
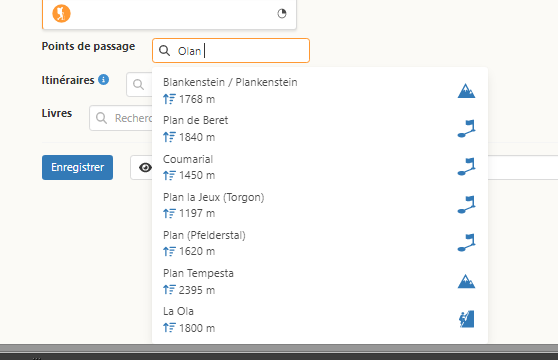
Oui, on dirait que l’initiale O n’est pas prise en compte…
Bernard
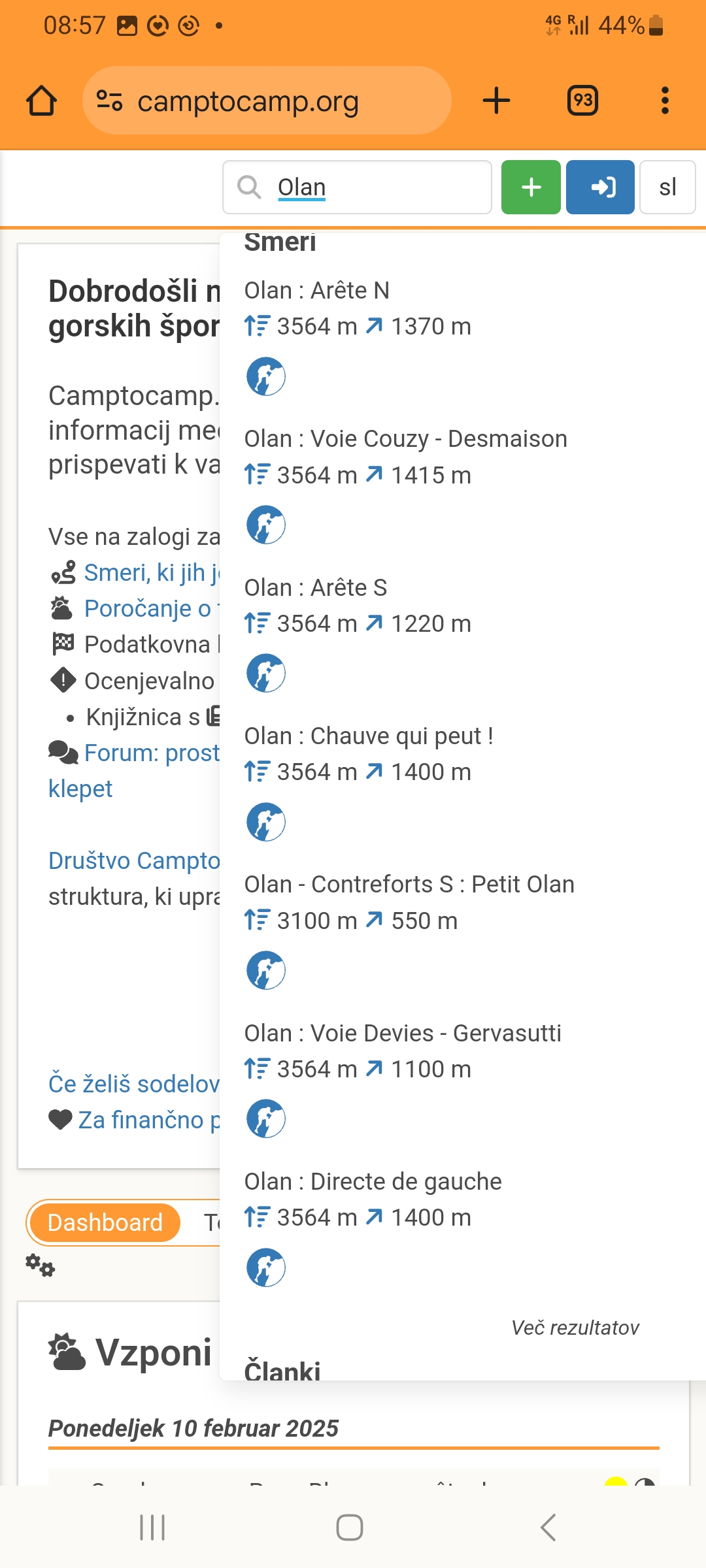
Avouons cependant qu’avec « Olan » dans le champ recherche et en scrollant un petit peu, on obtient les voies à l’Olan :
Je relance le sujet avec une suggestion : que la recherche de mots clés soit stricte. Pas de résultats proches ou autres trucs qui ne fonctionnent pas. Ou alors impérativement après les résultats stricts. J’imagine que la modification n’est pas très complexe, dans le cas du blocage des résultats « proches ».
Par exemple, une recherche de « lau bij » ne donne toujours pas la cascade intitulée « lau bij ».
Pour mémoire, le sujet avait également été abordé plus tôt ici : Topoguide, recherche par chaine de caractères dans le titre plus assez sélective
A mes yeux, c’est quand même un gros problème. C’est bête qu’on doive très souvent passer par google pour trouver un itinéraire, alors qu’une recherche interne existe.
4 Likes
Hello,
il nous manque un développeur bénévole pour améliorer notre elastic search…
1 Like
C’est clair que c’est dommage que l’outil de recherche ne retourne pas les résultats exacts directement.
D’après ce que j’ai compris (c’est à dire pas grand chose  ), le moteur d’indexation Elastic Search référence les contenus indexés en transformant les mots en radicaux, une forme minimaliste des mots en fonction de la langue (ce qui permet de s’affranchir des différentes orthographes liées aux accords de genre, nombre, conjugaison, etc.) et des éventuelles erreurs d’orthographe. Idem avec les mots clefs qui sont indiqués lors de la recherche. Cette approche a aussi l’intérêt de pouvoir combiner plusieurs termes de recherche, concernant potentiellement des pages différentes, par ex un élément du nom du sommet et un élément du nom de la voie, et dans n’importe quel ordre :
), le moteur d’indexation Elastic Search référence les contenus indexés en transformant les mots en radicaux, une forme minimaliste des mots en fonction de la langue (ce qui permet de s’affranchir des différentes orthographes liées aux accords de genre, nombre, conjugaison, etc.) et des éventuelles erreurs d’orthographe. Idem avec les mots clefs qui sont indiqués lors de la recherche. Cette approche a aussi l’intérêt de pouvoir combiner plusieurs termes de recherche, concernant potentiellement des pages différentes, par ex un élément du nom du sommet et un élément du nom de la voie, et dans n’importe quel ordre :
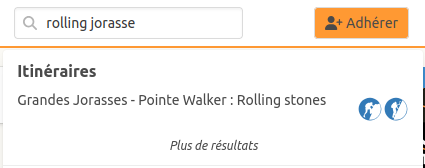
Une possibilité serait peut-être de commencer par faire des recherches exactes (en comparant la chaine de caractères exacte indiquée par l’utilisateur avec les noms des documents du topoguide) (sans passer par Elastic Search ?) pour trouver les résultats exacts d’abord. Puis de compléter par une seconde requête à Elastic Search pour compléter avec les résultats non exacts. Je ne sais pas si c’est possible de configurer Elastic Search pour fonctionner directement comme ça ou s’il faut le faire manuellement dans le code.
A voir aussi s’il y a moyen de demander à Elastic Search de ne pas transformer les termes indexés en radicaux trop simples ?
A noter qu’avec le système actuel, on arrive généralement à des résultats assez satisfaisants en indiquant des termes suffisamment discriminants.
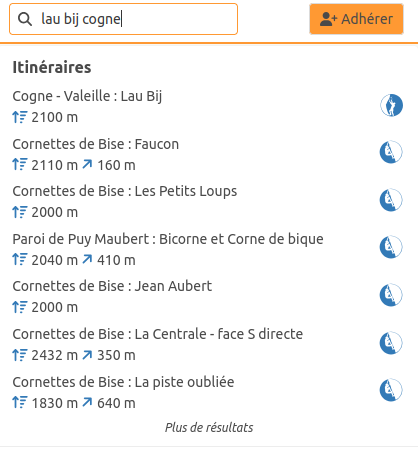
Par ex pour Lau Bij :
-
en tapant uniquement « Lau Bij » on ne trouve pas ce topo (probablement parce que Elastic Search cherche les termes « la » et « bi » (?) et donc retourne des trucs du style « bivouac », « lama » etc.
-
mais en ajoutant aussi « cogne » (ou « valeille »), on trouve bien le topo de Lau Bij en premier (il doit chercher les termes « la », « bi » et « co » ?) :
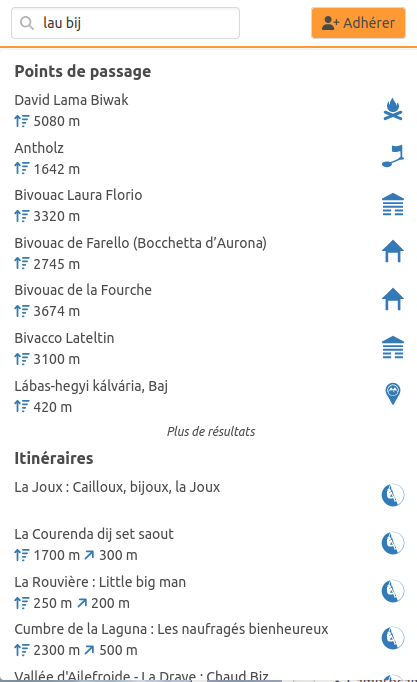
Bref ce serait bien d’améliorer le système de recherche actuel mais on arrive généralement à le faire fonctionner en l’état en précisant sa recherche.
2 Likes
Bon je relance une dernière fois le sujet… Je suis en train de me pencher sur une mise à jour des spots de dry, et c’est juste l’enfer :
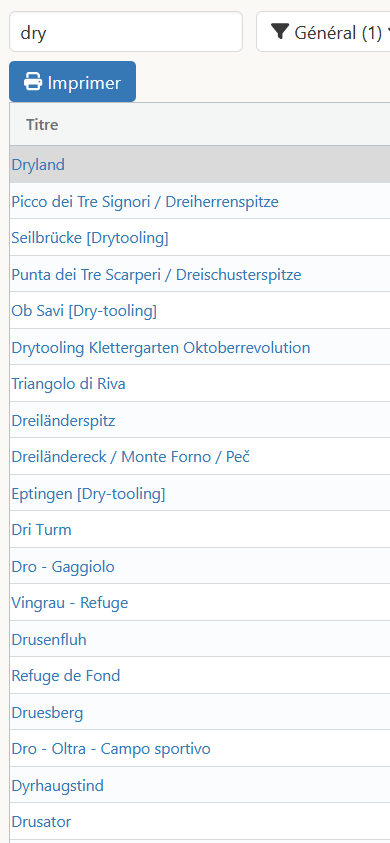
La majorité des résultats ne sont pas pertinents.
Ca serait cool de faire un hack temporaire pour désactiver la recherche proche. Ca je sais le faire, j’en avais parlé en MP. Vous aviez parlé de modifications en cours, sauf que ça fait des mois que c’est à l’arrêt, et c’est vraiment trop chiant, pour tout le monde.
Je recopie grosso modo ce que j’avais envoyé en MP :
Le hack le plus simple pour jouer là dessus serait de modifier la fuzziness du multimatch :
https://github.com/c2corg/v6_api/blob/master/c2corg_api/search/ init .py#L101
Si on se réfère à la doc elasticsearch :
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/common-options.html#fuzziness
Elle est actuellement en auto, et pour des termes de 3 ou plus caractères (approximativement 100% des mots importants), ça autorise un edit.
Le hack le plus simple serait de désactiver complètement ce paramètre. Sinon autoriser 1 edit à partir de 6-7 lettres je dirais. Et surtout jamais 2.
Petit rappel du fonctionnement du mode actuel :
AUTO
generates an edit distance based on the length of the term. For lengths:
0..2
must match exactly
3..5
one edit allowed
>5
two edits allowed
Et la modif proposée :
"fuzziness": 1,
"prefix_length": 6,
Le plus important serait de faire une modif « temporaire » rapidement, car ça fait bien trop longtemps que c’est un sacré merdier, qui ne convient à personne.
2 Likes
En effet ce n’est pas pertinent.
Mais dans ton cas, recherche « dry tooling ».
Tous les spots de dry et uniquement les spots de dry : Camptocamp.org
OK. Mais dans cet exemple, on ne risquait pas de trouver « dryland » avec la recherche de mot exact « dry ».
Par ailleurs j’ai corrigé 3 noms « drytooling » en « dry-tooling ».
Allez une dernière relance. Le hack est rapide et facile il me semble (pour le coup je suis assez sûr de mon coup !)
Juste pour le plaisir, même si ça a déjà été posté :
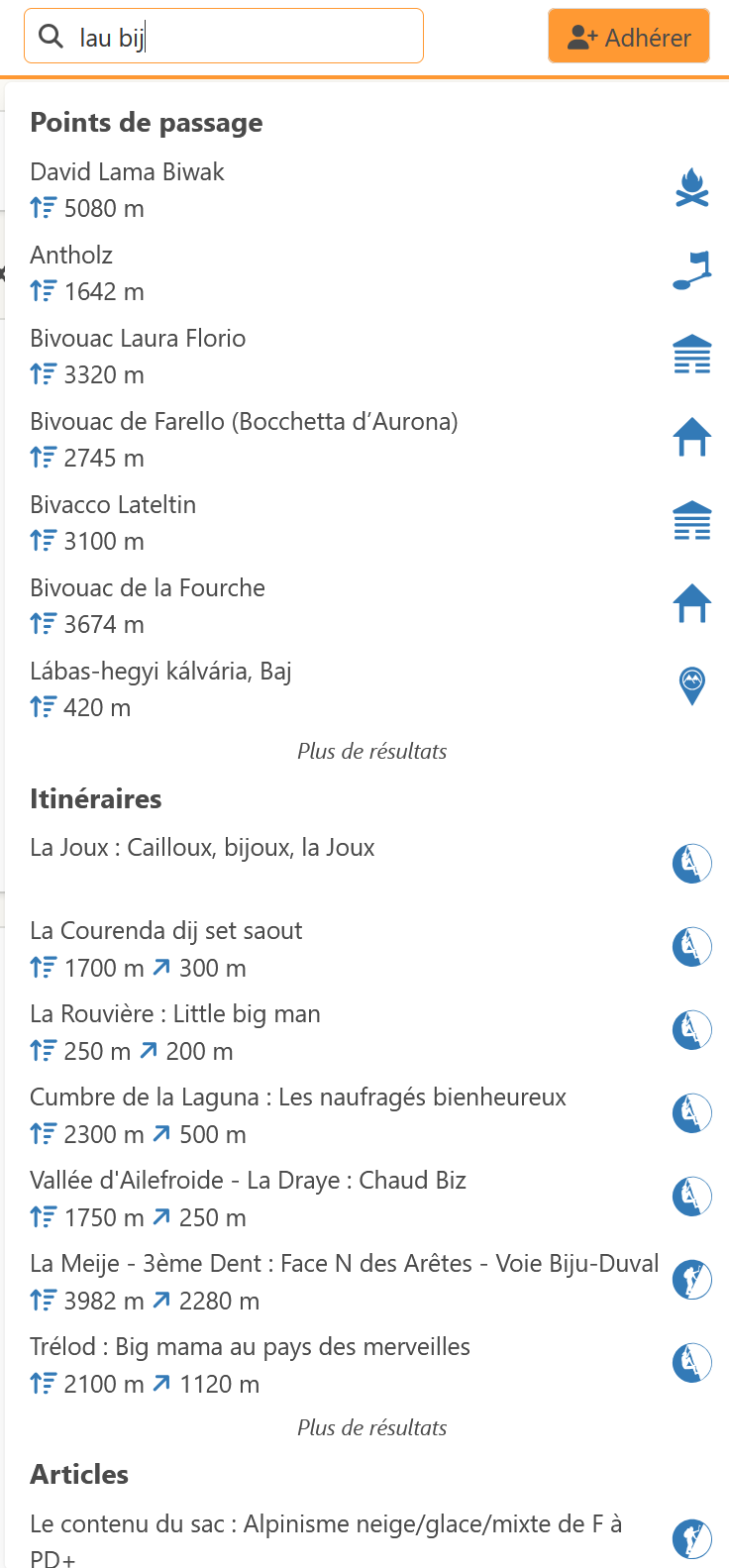
https://www.camptocamp.org/routes/487432/fr/cogne-valeille-lau-bij
1 Like
Ou pas, ça fait tellement longtemps qu’on se traîne ce sujet très impactant… Il ne faut surtout pas se lasser de le rappeler!
1 Like
J’ai du mal à comprendre si c’est sarcastique ou non. En tous cas dans mon usage c’est effectivement très impactant. (et très simple à corriger avant un fix propre)
Ah non, zéro sarcasme! Simplement, C2C ça fonctionne sur la base de très peu de personnes effectivement investies, et donc beaucoup de choses ne parviennent malheureusement pas à être faites
2 Likes
Comment on fait pour avancer dans ce problème de recherche ?
Pourquoi ne pas tester la proposition d’Adrien pendant quelque temps et la valider ou non après test ?
Les recherches non abouties sont un problème sérieux je trouve.
4 Likes
Très bonne question
C’est quand même dommage que le fonctionnement classique de la plupart des utilisateurs soit de passer par une recherche google pour retrouver les itinéraires, simplement car la recherche interne ne fonctionne pas correctement. J’en ai parlé autour de moi, et je ne suis clairement pas le seul à passer par google…
6 Likes
Idem
Ça fait longtemps que j’ai abandonné la recherche interne et passe par Google.
Pour info la recherche sur le site promogrimpe est juste parfaite…
C’est pourtant pas un gros truc comme c2c…
Étrange.
S’en inspirer serait un gros plus.
Petit up rituel.
Et une question au passage : pourquoi ma suggestion n’est pas implémentée ? En vrai, ça ne coûte rien, c’est quelques lignes à modifier, un retour en arrière est facile, et si ça casse la recherche, ce n’est pas trop gênant vu comme elle fonctionne mal actuellement. Et de toute manière, vu la complexité de la modif, ça ne risque pas vraiment de casser quoi que ce soit…
2 Likes